
计算权重是一种常见的分析方法,在实际研究中,需要结合数据的特征情况进行选择,比如数据之间的波动性是一种信息量,那么可考虑使用CRITIC权重法或信息量权重法;也或者专家打分数据,那么可使用AHP层次法或优序图法。
本文列出常见的权重计算方法,并且对比各类权重计算法的思想和大概原理,使用条件等,便于研究人员选择出科学的权重计算方法。
首先列出常见的8类权重计算方法,如下表所示:
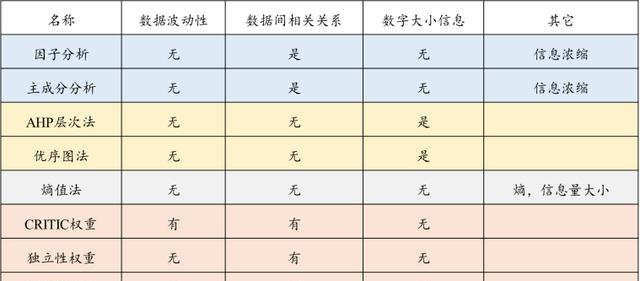
计算权重方法汇总
这8类权重计算的原理各不相同,结合各类方法计算权重的原理大致上可分成4类,分别如下:
第一类为因子分析和主成分法;此类方法利用了数据的信息浓缩原理,利用方差解释率进行权重计算;
第二类为AHP层次法和优序图法;此类方法利用数字的相对大小信息进行权重计算;
第三类为熵值法(熵权法);此类方法利用数据熵值信息即信息量大小进行权重计算;
第四类为CRITIC、独立性权重和信息量权重;此类方法主要是利用数据的波动性或者数据之间的相关关系情况进行权重计算。
第一类、信息浓缩(因子分析和主成分分析)
计算权重时,因子分析法和主成分法均可计算权重,而且利用的原理完全一模一样,都是利用信息浓缩的思想。因子分析法和主成分法的区别在于,因子分析法加带了"旋转’的功能,而主成分法目的更多是浓缩信息。
"旋转’功能可以让因子更具有解释意义,如果希望提取出的因子具有可解释性,一般使用因子分析法更多;并非说主成分出来的结果就完全没有可解释性,只是有时候其解释性相对较差而已,但其计算更快,因而受到广泛的应用。
比如有14个分析项,该14项可以浓缩成4个方面(也称因子或主成分),此时该4个方面分别的权重是多少呢?此即为因子分析或主成分法计算权重的原理,它利用信息量提取的原理,将14项浓缩成4个方面(因子或主成分),每个因子或主成分提取出的信息量(方差解释率)即可用于计算权重。接下来以SPSSAU为例讲解具体使用因子分析法计算权重。

因子分析、主成分分析

如果说预期14项可分为4个因子,那么可主动设置提取出4个因子,相当于14句话可浓缩成4个关键词。
但有的时候并不知晓到底应该多少个因子更适合,此时可结合软件自动推荐的结果和专业知识综合进行判断。点击SPSSAU"开始分析’后,输出关键表格结果如下:
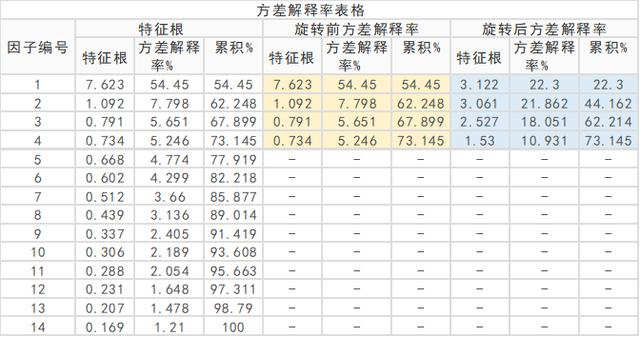
上表格中黄色底纹为"旋转前方差解释率’,其为没有旋转前的结果,实质上就是主成分的结果。如果是使用因子分析,一般使用"旋转后方差解释率’对应的结果。
结果中方差解释率%表示每个因子提取的信息量,比如第1个因子提取信息量为22.3%,第2个因子为21.862%,第3个因子为18.051%,第4个因子为10.931%。并且4个因子累积提取的信息量为73.145%。
那么当前4个因子可以表述14项,而且4个因子提取出14项的累积信息量为73.145%。现希望得到4个因子分别的权重,此时可利用归一化处理,即相当于4个因子全部代表了整体14项,那么第1个因子的信息量为22.3%/73.145%=30.49%;类似的第2个因子为21.862%/73.145%=29.89%;第3个因子为18.051%/73.145%=24.68%;第4个因子为10.931%/73.145%=14.94%。
如果是使用主成分法进行权重计算,其原理也类似,事实上结果上就是"旋转前方差解释率’值的对应计算即可。
使用浓缩信息的原理进行权重计算时,只能得到各个因子的权重,无法得到具体每个分析项的权重,此时可继续结合后续的权重方法(通常是熵值法),得到具体各项的权重,然后汇总在一起,最终构建出权重体系。
通过因子分析或主成分分析进行权重计算的核心点即得到方差解释率值,但在得到权重前,事实上还有较多的准备工作,比如本例子中提取出4个因子,为什么是4个不是5个或者6个;这是结合专业知识和分析方法提取的其它指标进行了判断;以及有的时候某些分析项并不适合进行分析,还需要进行删除处理后才能进行分析等,此类准备工作是在分析前准备好,具体可参考SPSSAU帮助手册里面有具体的实际案例和视频说明等。
第二类、数字相对大小(AHP层次法和优序图法)
计算权重的第二类方法原理是利用数字相对大小,数字越大其权重会相对越高。此类原理的代表性方法为AHP层次法和优序图法。
1. AHP层次法
AHP层次分析法的第一步是构建判断矩阵,即建立一个表格,表格里面表述了分析项的相对重要性大小。比如选择旅游景点时共有4个考虑因素,分别是景色,门票,交通和拥护度,那么此4个因素的相对重要性构建出判断矩阵如下表:
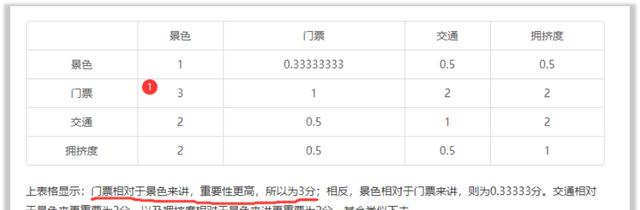
表格中数字代表相对重要的大小,比如门票和景色的数字为3分,其说明门票相对于景色来讲,门票更加重要。当然反过来,景色相对于门票就更不重要,因此得分为1/3=0.3333分。
AHP层次分析法正是利用了数字大小的相对性,数字越大越重要权重会越高的原理,最终计算得到每个因素的重要性。AHP层次分析法一般用于专家打分,直接让多位专家(一般是4~7个)提供相对重要性的打分判断矩阵,然后进行汇总(一般是去掉最大值和最小值,然后计算平均值得到最终的判断矩阵,最终计算得到各因素的权重。
SPSSAU共有两个按键可进行AHP层次分析法计算。
如果是问卷数据,比如本例中共有4个因素,问卷中可以直接问“景色的重要性多大?”,“门票的重要性多大?”,“交通的重要性多大?”,“拥护度的重要性多大?”。可使用SPSSAU【问卷研究】--【权重】,系统会自动计算平均值,然后直接利用平均值大小相除得到相对重要性大小,即自动计算得到判断矩阵而不需要研究人员手工输入。

AHP层次分析:【问卷研究】--【权重】
如果是使用【综合评价】--【AHP层次分析法】,研究人员需要自己手工输入判断矩阵。
【综合评价】--【AHP层次分析】
2. 优序图法
除了AHP层次分析法外,优序图法也是利用数字的相对大小进行权重计算。
数字相对更大时编码为1,数字完全相同为0.5,数字相对更小编码为0。然后利用求和且归一化的方法计算得到权重。比如当前有9个指标,而且都有9个指标的平均值,9个指标两两之间的相对大小可以进行对比,并且SPSSAU会自动建立优序图权重计算表并且计算权重,如下表格:
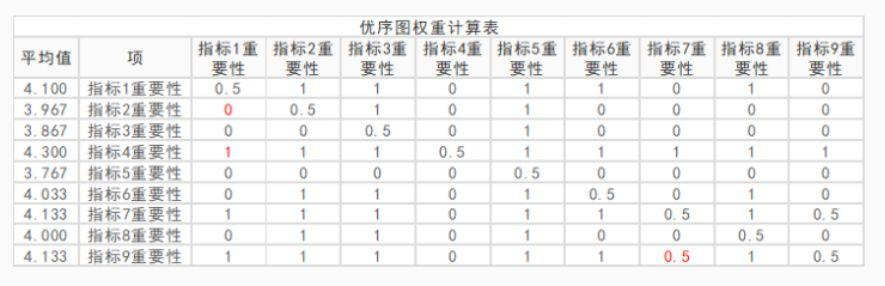
优序图法
上表格中数字0表示相对不重要,数字1表示相对更重要,数字0.5表示一样重要。
比如指标2的平均值为3.967,指标1的平均值是4.1,因此指标1不如指标2重要;指标4的平均值为4.3,重要性高于指标1。也或者指标7和指标9的平均得发均为4.133分,因此它们的重要性一样,记为0.5。
结合上面最关键的优序图权重计算表,然后得到各个具体指标(因素)的权重值。
优序图法适用于专家打分法,专家只需要对每个指标的重要性打分即可,然后让软件SPSSAU直接结合重要性打分值计算出相对重要性指标表格,最终计算得到权重。
优序图法和AHP法的思想上基本一致,均是利用了数字的相对重要性大小计算。一般在问卷研究和专家打分时,使用AHP层次分析法或优序图法较多。
第三类、信息量(熵值法)
计算权重可以利用信息浓缩,也可利用数字相对重要性大小,除此之外,还可利用信息量的多少,即数据携带的信息量大小(物理学上的熵值原理)进行权重计算。
熵值是不确定性的一种度量。信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性越大,熵也越大。因而利用熵值携带的信息进行权重计算,结合各项指标的变异程度,利用信息熵这个工具,计算出各项指标的权重,为多指标综合评价提供依据。
在实际研究中,通常情况下是先进行信息浓缩法(因子或主成分法)得到因子或主成分的权重,即得到高维度的权重,然后想得到具体每项的权重时,可使用熵值法进行计算。
SPSSAU在【综合评价】模块中提供此方法,其计算也较为简单易懂,直接把分析项放在框中即可得到具体的权重值。
【综合评价】--【熵值法】
第四类、数据波动性或相关性(CRITIC、独立性和信息量权重)
可利用因子或主成分法对信息进行浓缩,也可以利用数字相对大小进行AHP或优序图法分析得到权重,还可利用物理学上的熵值原理(即信息量携带多少)的方法得到权重。除此之外,数据之间的波动性大小也是一种信息,也或者数据之间的相关关系大小,也是一种信息,可利用数据波动性大小或数据相关关系大小计算权重。
1. CRITIC权重法
CRITIC权重法是一种客观赋权法。其思想在于用两项指标,分别是对比强度和冲突性指标。对比强度使用标准差进行表示,如果数据标准差越大说明波动越大,权重会越高;冲突性使用相关系数进行表示,如果指标之间的相关系数值越大,说明冲突性越小,那么其权重也就越低。权重计算时,对比强度与冲突性指标相乘,并且进行归一化处理,即得到最终的权重。使用SPSSAU时,自动会建立对比强度和冲突性指标,并且计算得到权重值。
CRITIC权重法适用于这样一类数据,即数据稳定性可视作一种信息,并且分析的指标或因素之间有着一定的关联关系时。比如医院里面的指标:出院人数、入出院诊断符合率、治疗有效率、平均床位使用率、病床周转次数共5个指标;此5个指标的稳定性是一种信息,而且此5个指标之间本身就可能有着相关性。因此CRITIC权重法刚好利用数据的波动性(对比强度)和相关性(冲突性)进行权重计算。
SPSSAU综合评价里面提供CRITIC权重法,如下图所示:
【综合评价】--【CRITIC权重】
2. 独立性权重法
独立性权重法是一种客观赋权法。其思想在于利用指标之间的共线性强弱来确定权重。如果说某指标与其它指标的相关性很强,说明信息有着较大的重叠,意味着该指标的权重会比较低,反之如果说某指标与其它指标的相关性较弱,那么说明该指标携带的信息量较大,该指标应该赋予更高的权重。
独立性权重法仅仅只考虑了数据之间相关性,其计算方式是使用回归分析得到的复相关系数R值来表示共线性强弱(即相关性强弱),该值越大说明共线性越强,权重会越低。比如有5个指标,那么指标1作为因变量,其余4个指标作为自变量进行回归分析,就会得到复相关系数R 值,余下4个指标重复进行即可。计算权重时,首先得到复相关系数R 值的倒数即1/R ,然后将值进行归一化即得到权重。
比如某企业计划招聘5名研究岗位人员,应聘人员共有30名,企业进行了五门专业方面的笔试,并且记录下30名应聘者的成绩。由于专业课成绩具有信息重叠,因此不能简单的直接把成绩加和用于评价应聘者的专业素质。因此使用独立性权重进行计算,便于得到更加科学客观的评价,选出最适合的应聘者。
SPSSAU综合评价里面提供独立性权重法,如下图所示:
【综合评价】--【独立性权重】
3. 信息量权重法
信息量权重法也称变异系数法,信息量权重法是一种客观赋权法。其思想在于利用数据的变异系数进行权重赋值,如果变异系数越大,说明其携带的信息越大,因而权重也会越大,此种方法适用于专家打分、或者面试官进行面试打分时对评价对象(面试者)进行综合评价。
比如有5个水平差不多的面试官对10个面试者进行打分,如果说某个面试官对面试者打分数据变异系数值较小,说明该面试官对所有面试者的评价都基本一致,因而其携带信息较小,权重也会较低;反之如果某个面试官对面试者打分数据变异系数值较大,说明该面试官对所有面试者的评价差异较大,因而其携带信息大,权重也会较高。
SPSSAU综合评价里面提供信息量权重法,如下图所示:
【综合评价】--【信息量权重】
对应方法的案例说明、结果解读这里不再一一详述,有兴趣可以参考SPSSAU帮助手册。